
BacklogでCI/CDをする
本記事はヌーラボが運営しているプロジェクト・タスク管理ツールである「backlog」を使って、AWSのリソースのCI/CDを実現します。

![]()
この記事を作成するに当たり、下記を参考に致しました。
※当時は大変助かりました。ありがとうございました。

https://locaop.co.jp/tech/backlog-git-aws-code-pipeline

上記の記事では実現できていなかった、ブランチ毎の対応もさせています。
また、Lambdaで利用するdulwichなどのパッケージインストール部分が抜けているため補足を紹介しています。
BacklogでCI/CDをする課題
Backlog自体は非常に使いやすいツールなのですが、AWSのCI/CDに関しては難易度が高いです。
AWSでCI/CDを実現するには、CodePipelineを使用します。
CodePipelineではソースコードを指定することでCodePipelineを着火(スタート)させることができるのですが、backlogのGitリポジトリは未対応となっています。
そのため、backlogで管理しているGitコードからAWSリソースへCI/CDするには工夫が必要です。
BacklogでCI/CDを実現するための構成と機能
構成
構成は下記となります。
backlogのリポジトリにgit pushをするだけでCodePipelineが着火、デプロイまで実施してくれます。それぞれの役割をご紹介します。
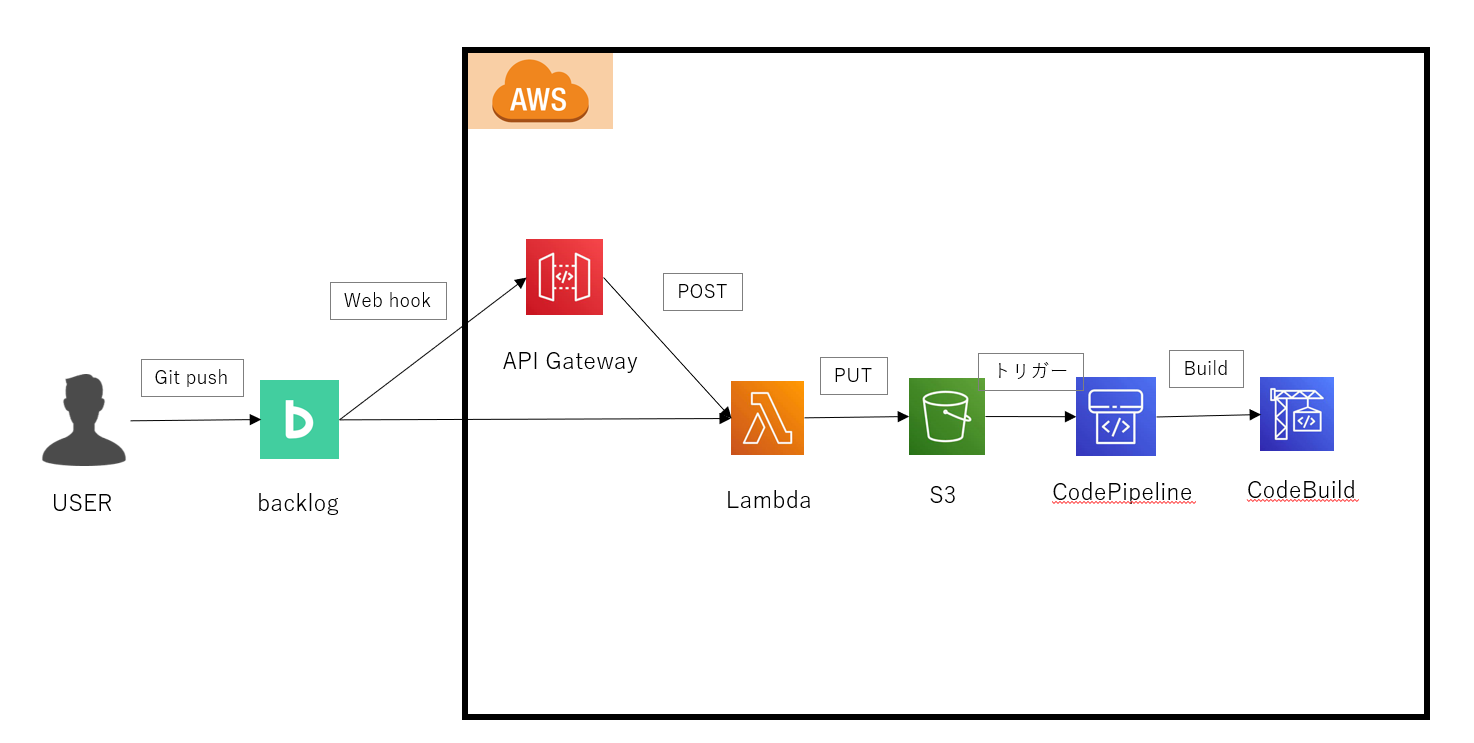
Backlog
BacklogでCI/CDを実現するために、「Webhook」機能を利用します。
Git pushをトリガーにして、データを次の場所へ送付する役割を果たします。
API Gateway
Webhookの送信先です。先に作成しておいて、API GatewayのURLを作成し、backlog側にwebhookの送信先を記載します。
Lambdaと連携し、Lambda宛にPOSTメソッドを実行します。
Lambda
Pythonで実行し、Backlogから送られてきたブランチやリポジトリをif分岐で判定し、ソースコードをzip化、zipファイルに名前を付けて、所定のS3へPUTします。
S3
zip化されたファイル置き場です。バージョニング設定を有効にしてS3でも冗長性を確保します。
バケットは1つで「CICD用」という感じで作成します。その中にプロジェクト毎、ブランチ毎のファイルが設置されます。
CodePipeline
S3のPUTをソースコードに設定して、ファイル設置をトリガーにCodePipelineをスタートさせます。
CodeBuild
ソースコードのbuildを行います。
ソースコード内のbuildspec.yml内に記載されているコマンドを実行してbuildをします。
デプロイするソースコードの種類(React/Vue/Dockerなど)によってコマンドは異なります。
CI/CD構築手順
実際に構築する手順の解説です。
①S3
S3から作成しておきます。
バージョニング設定を有効にして、バケット名は何でも良いです。
バケットの直下にzipファイルを設置していきます。
②backlog
公式ページよりwebhook設定をしてください。
https://support-ja.backlog.com/hc/ja/articles/360036147713-Webhook
Git pushをトリガーにします。
webhook URLは後に作成するAPI GatewayのURLを入力します。
③Lambda
Lambdaを作成します。
ランタイム:Python3.1
アーキテクチャ:x86_64
ロール:新規作成
dulwich

上記を参考にして、Pythonのdulwichのパッケージをzipで作成しておきます。
作成後は該当のLambdaにアップロードします。下記画面の右側「アップロード元」です。

一般設定
ソースコードの容量によりますが、タイムアウトはデフォルトのものだと先ず足りません。最低でも1分程度にしてきましょう。

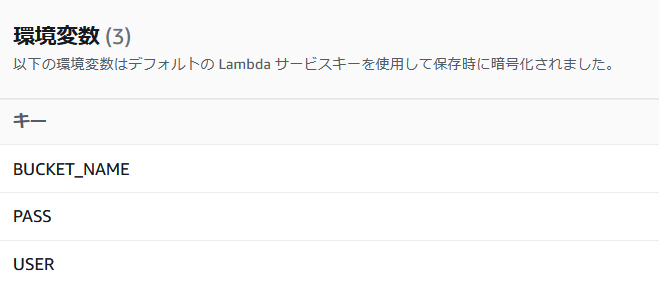
環境変数
以下3つを作成しておいてください。
user/passはbacklogのGit cloneする際のユーザーとパスワードです。
ソースコード
下記を参考にしてください。
backlogのwebURL、ブランチ名、リポジトリ名を入力してください。
import json
import urllib.parse
import os
import tempfile
import shutil
import boto3
import pprint
import glob
from dulwich import porcelain
# 環境変数の呼び出し
BUCKET_NAME = os.environ['BUCKET_NAME']
USER = os.environ['USER']
PASS = os.environ['PASS']
#backlogから送られてくるJSONの参照先を定義
def lambda_handler(event, context):
print(event)
branch = event['content']['ref']
REPOSITORY = event['content']['repository']['name']
print(branch)
print(REPOSITORY)
# backlogへのgit cloneコマンド作成
if branch == "refs/heads/master" and REPOSITORY == "xxxxx":
repository = "xxxxx"
url ="https://caretz.backlog.com/git/xxxxx/xxxxx"
branch = "xxxxx"
print(f"repository:{repository} branch:{branch} uri:{url}")
elif branch == "refs/heads/develop" and REPOSITORY == "xxxxx":
repository = "xxxxx"
url ="https://caretz.backlog.com/git/xxxxx/xxxxx"
branch = "xxxxx"
print(f"repository:{repository} branch:{branch} uri:{url}")
else:
print("not applicable")
exit()
# gitパスの生成
site = urllib.parse.urlparse(url)
userStr = urllib.parse.quote(USER)
passStr = urllib.parse.quote(PASS)
uri = site.scheme +"://" + userStr + ":" + passStr +"@" + site.netloc + site.path + ".git"
# 作業ディレクトリの生成
tmpDir = tempfile.mkdtemp()
try:
if branch == "xxxxx" and REPOSITORY == "xxxxx":
porcelain.clone(uri, tmpDir, branch=b"xxxxx")
print("git clone success")
zipFileName = tmpDir+ '/' + "xxxxx-zip"
ZIP_FILE_NAME = "xxxxx-zip"
elif branch == "xxxxx" and REPOSITORY == "xxxxx":
porcelain.clone(uri, tmpDir, branch=b"xxxxx")
print("git clone success")
zipFileName = tmpDir+ '/' + "xxxxx-zip"
ZIP_FILE_NAME = "xxxxx-zip"
else:
print("Not applicable2")
shutil.make_archive(zipFileName, 'zip', tmpDir )
print(zipFileName)
print("zip success")
# S3への設置
s3 = boto3.client('s3')
s3.upload_file(zipFileName + '.zip', BUCKET_NAME, ZIP_FILE_NAME)
print("s3 upload success")
except Exception as e:
print("ERROR" + e)
# 後始末
shutil.rmtree(tmpDir)④API Gateway
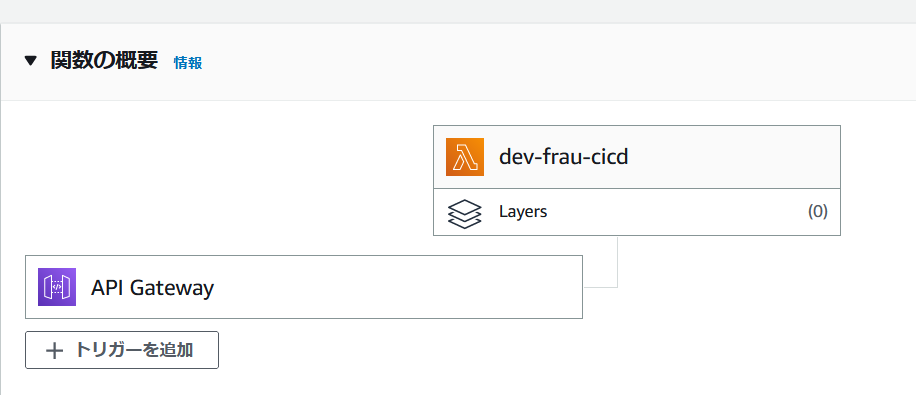
POSTメソッドを作成、実行先に③で作成したLambdaを指定します。
ステージに出力される「URLの呼び出し」のURLが出力されます。
これがAPIエンドポイントとなります。Lambda側にも同様にトリガーが追加されているはずです。
その他の設定は不要です。
⑤CodePipeline・CodeBuild
ソースコードの指定を①で作成したS3に設定します。
その他の設定はソースコードの言語によるため割愛します。
React/Vueは下記で紹介しています。

エラー時の切り分け
詳細に書きましたが、これですんなり作成できるとは思っていません。
エラーが少なからず発生すると思います。エラー時の切り分け方法をご紹介しておきます。
Backlog
backlogでエラーが発生している場合は、backlogのwebhookの実行ページで履歴が確認できます。
また、送信しているJSONも表示されますので、Lambdaの定義の箇所も切り分けが可能です。
Lambda
Lambdaが成功しているか失敗しているかを確認します。ログも出力されるため切り分けが可能です。
リポジトリやブランチ名、バケット名に間違いがないか確認しましょう。
print関数を使って、適宜デバックをしてください。
zip化でコケているのか、ブランチ名がきちんと指定できているか、printで表示させます。
S3
ファイルが作成されているか確認しましょう。作成されていない場合は上記のbacklog/lambda/API Gatewayのどれかが起因です。
zipファイルがある場合はダウンロードして中身がbacklogのリポジトリのソースコードと同じであるか確認しましょう。
CodePipeline/CodeBuild
それぞれCloudwatch logsにエラーログが出力されるため、そちらを確認しましょう。
CI/CDの料金
実際に掛かっている費用をこちらで紹介しています。
AWSの効果的な学習方法は?

最後に、AWSの効果的な学習方法をご紹介します。
自学自習はUdemy講座
オンラインプラットフォームであるUdemyは安価で手軽にAWSの学習が可能です。
しかし、上記で紹介したような実際のAWSエンジニアが実施している構築スキルまでは教えてくれません。初心者~中級者向けの講座が多くなっています。

私も受講した、初心者向けAWS講座を下記記事でまとめています。ご参考ください。

{kind=link}